Every day, companies face a flood of data—from social media likes to smart device sensors—but old tools like Hadoop (which stores data on slow hard drives) can’t keep up. They’re like delivery trucks in a world that now needs jets.
That’s where Apache Spark shines. Born in 2014, it’s a free, super-fast system that:
✔️ Processes data 100x faster by using computer memory (like your laptop’s RAM) instead of hard drives
✔️ Handles real-time updates (like fraud alerts) and AI tasks (like Netflix recommendations) in one place
✔️ Powers companies you know—Tesla uses it for self-driving cars; Spotify for music suggestions
In this guide, you’ll discover how Spark’s architecture (illustrated below), unified APIs, and real-world applications make it the Swiss Army knife of big data. We’ll break down its core components with practical examples, and explore how industry leaders like Netflix, Tesla, and PayPal leverage Spark to turn massive data streams into actionable insights at unprecedented scale.
What is Apache Spark?
The Big Data Revolution: Why Spark Was Needed
Before diving into Spark, let’s understand the problem it solves: Big Data.
Big Data isn’t just a buzzword—it’s a fundamental shift in how we process information. It refers to massive datasets that are too large, complex, or fast-moving for traditional databases to handle. These datasets come in three forms:
- Structured Data (e.g., spreadsheets, SQL tables)
- Unstructured Data (e.g., social media posts, videos)
- Semi-Structured Data (e.g., JSON files, sensor logs)

By 2025, the world will generate 463 exabytes of data every day—equivalent to 212 million DVDs! Traditional tools like MySQL or Excel choke on this scale, leading to slow processing, high costs, and missed insights.
Apache Spark is an open-source, distributed computing framework designed to process massive datasets quickly and efficiently across clusters of computers. Unlike traditional systems that rely on slow disk-based storage (like Hadoop MapReduce), Spark performs computations in-memory, dramatically speeding up data processing—often by 100x for iterative workloads like machine learning algorithms.
Why “Distributed” Computing?
In simple terms, “distributed” means Spark breaks large datasets into smaller chunks and processes them in parallel across multiple machines (nodes). This approach allows Spark to handle petabyte-scale data that would overwhelm a single computer.
Key Features of Spark
- In-Memory Processing: Spark stores intermediate data in RAM instead of writing it to disk, reducing latency.
- Example: Training a recommendation model requires repeating calculations on the same dataset. Spark keeps this data in memory, while Hadoop would reread it from disk each time.
- Unified Engine: Spark integrates multiple workloads under one framework:
- Batch Processing: Scheduled jobs (e.g., nightly sales reports).
- Real-Time Streaming: Live data (e.g., fraud detection in transactions).
- Machine Learning: Built-in libraries (e.g., predicting customer churn).
- Graph Processing: Analyzing networks (e.g., social media connections).
- Developer-Friendly APIs: Spark supports Python (PySpark), Scala, Java, and R, with high-level abstractions like DataFrames and SQL.
- For Beginners: Think of DataFrames as Excel tables but optimized for big data.
Why Was Spark Created? The Limitations of Hadoop
The Big Data Bottleneck: When Hadoop Hit Its Limits
In the early 2000s, Hadoop revolutionized data processing by allowing distributed storage (HDFS) and computation (MapReduce) across clusters of commodity hardware. It was groundbreaking—until data volumes exploded, and modern use cases demanded more speed and flexibility.
4 Fundamental Flaws of Hadoop MapReduce
- Disk-Based Slowness
- Problem: Every MapReduce job wrote intermediate data to disk between steps, creating massive I/O bottlenecks.
- Impact: Iterative tasks (like machine learning) became excruciatingly slow. Training a model might take 10 hours instead of 10 minutes.
- Spark’s Fix: In-memory caching keeps working datasets in RAM, eliminating repetitive disk reads.
- Batch-Only Processing
- Problem: Hadoop could only process data in batches (scheduled jobs), making real-time analytics impossible.
- Impact: A fraud detection system couldn’t flag suspicious transactions until hours later.
- Spark’s Fix: Structured Streaming enables micro-batch and event-time processing for live data.
- Complex, Low-Level APIs
- Problem: Writing MapReduce jobs required verbose Java code, even for simple tasks like filtering data.
- Impact: Teams spent weeks building pipelines that should take days.
- Spark’s Fix: High-level APIs (Python/Scala DataFrames, SQL) let users focus on logic, not plumbing.
- Fragmented Ecosystem
- Problem: Hadoop needed separate tools for SQL (Hive), ML (Mahout), and graphs (Giraph), each with its own learning curve.
- Impact: Integrating these tools was error-prone and inefficient.
- Spark’s Fix: A unified engine with built-in libraries (Spark SQL, MLlib, GraphX).

The Turning Point: AMPLab and Spark’s Birth
In 2009, UC Berkeley’s AMPLab began developing Spark to address these gaps. Their goal: retain Hadoop’s scalability while adding speed and usability. Key innovations:
- Resilient Distributed Datasets (RDDs): Fault-tolerant data structures enabling in-memory processing.
- Lazy Evaluation: Optimizes execution plans before running jobs.
- Interactive Shell: Allowed data scientists to query data on-the-fly (unlike Hadoop’s compile-and-wait cycle).
Hadoop vs. Spark: A Side-by-Side Comparison
| Challenge | Hadoop | Spark |
|---|---|---|
| Processing Model | Disk-based batch | In-memory batch/streaming |
| Ease of Use | Complex Java API | Python/Scala/R/SQL support |
| Latency | High (minutes to hours) | Low (sub-second to seconds) |
| Machine Learning | Requires Mahout (separate tool) | Built-in MLlib |
Why This Matters Today
Spark’s design didn’t just patch Hadoop’s issues—it reimagined distributed computing for the AI/real-time era. For example:
- Netflix reduced recommendation model training from days to minutes.
- Uber processes millions of ride events per second for dynamic pricing.
How Does Apache Spark Work? Understanding the Architecture
Spark’s architecture is built for speed, scalability, and fault tolerance. Here’s a breakdown:
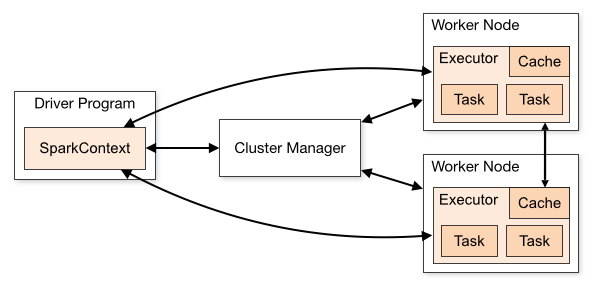
When you first hear about Apache Spark, it might sound like a complex system—and in some ways, it is. But at its core, Spark is just a powerful engine for processing huge amounts of data quickly by breaking the work into smaller pieces and distributing it across many computers.
To truly understand how Spark works, we need to explore its core architecture—the way its different components interact to make big data processing fast, reliable, and scalable.
1. The Driver Program: The Brain Behind the Operation
Imagine you’re the manager of a big construction project. You don’t actually lift the bricks or pour the concrete yourself—instead, you:
- Decide what needs to be done.
- Assign tasks to workers.
- Keep track of progress.
In Spark, the Driver Program does exactly this. When you write a Spark application (for example, a program that analyzes sales data), the Driver takes your instructions and turns them into a step-by-step plan.
What Does the Driver Actually Do?
- Translates your code into an execution plan.
- Breaks the work into small tasks that can run in parallel.
- Sends these tasks to worker machines (called Executors).
- Monitors progress and collects results.
The Driver doesn’t store or process the data itself—it just manages the workflow.
2. Executors: The Workers That Do the Heavy Lifting
If the Driver is the project manager, then Executors are the construction workers. They are the ones who actually process the data.
How Executors Work
- Each Executor runs on a different machine in the cluster.
- They load data (either from disk or memory).
- They perform computations (filtering, sorting, aggregating).
- They store intermediate results in memory for faster processing.
- Finally, they send results back to the Driver.
Why Is In-Memory Processing So Important?
Traditional systems (like Hadoop) read and write data to disk constantly, which is slow. Spark keeps as much data as possible in RAM (memory), making it up to 100x faster for certain tasks.
3. The Cluster Manager: The Resource Allocator
A big construction project needs someone to assign workers, tools, and materials efficiently. In Spark, this role is handled by the Cluster Manager.
What Does the Cluster Manager Do?
- Decides how many Executors should run.
- Assigns CPU and memory to each Executor.
- Handles failures (if a machine crashes, it reassigns tasks).
Spark works with different Cluster Managers:
- YARN (used in Hadoop environments).
- Kubernetes (popular for cloud deployments).
- Standalone Mode (for simpler setups).
Without the Cluster Manager, Spark wouldn’t know how to distribute work efficiently.
4. Resilient Distributed Datasets (RDDs): Spark’s Secret to Fault Tolerance
One of Spark’s most important innovations is the Resilient Distributed Dataset (RDD).
What Are RDDs?
- They are immutable (unchangeable) collections of data.
- They split large datasets into smaller partitions stored across machines.
- They track lineage—a log of how each piece of data was created.
Why Are RDDs Important?
- Parallel Processing: Different Executors can work on different partitions at the same time.
- Fault Tolerance: If an Executor crashes, Spark can reconstruct lost data using the lineage log.
Example:
Imagine you’re building a puzzle, and someone spills coffee on some pieces. Instead of starting over, you use the picture on the box (lineage) to reprint just the missing pieces. That’s how RDDs handle failures!
Putting It All Together: How Data Flows in Spark
Let’s say you want to analyze a huge log file to find all error messages. Here’s how Spark processes it:
- You write a simple command (e.g., “Filter logs for errors”).
- The Driver converts this into tasks (e.g., “Read file chunk 1, filter errors, return results”).
- The Cluster Manager assigns these tasks to available Executors.
- Each Executor loads a portion of the log file, filters it, and keeps results in memory.
- Finally, the Driver collects all filtered results and displays them.
If an Executor fails midway, Spark automatically reassigns its tasks to another Executor and rebuilds lost data using RDD lineage.
At first, Spark’s architecture might seem complex, but it’s built on simple principles:
- A Driver manages tasks.
- Executors do the actual work.
- A Cluster Manager assigns resources.
- RDDs ensure data is processed efficiently and reliably.
For a detailed breakdown of spark architecture, check out our deep dive:
🔗 The Anatomy of Spark Architecture: A Symphony of Distributed Processing
Now that you understand how Spark works under the hood, you’ll better appreciate why it’s the go-to tool for big data processing!
Why Use Apache Spark? Key Advantages
Spark’s dominance in big data stems from its unique strengths:
1. Speed: In-Memory Computing for Instant Results
- In-memory computing minimizes disk I/O.
- Optimized execution plans via Catalyst Optimizer (for Spark SQL).
Spark outperforms traditional systems by executing computations directly in RAM, avoiding slow disk I/O. Its optimized execution engine (Catalyst Optimizer for SQL, Tungsten for Python) analyzes queries to create the most efficient processing plan. For iterative algorithms like machine learning, this delivers 100x faster performance versus disk-based systems like Hadoop. The result? Real-time analytics that were previously impossible, from fraud detection to live recommendations.
2. Ease of Use: Intuitive APIs for Faster Development
- High-level APIs (e.g.,
df.filter("age > 30")). - Interactive shells (Spark Shell, Jupyter notebooks).
Spark replaces complex MapReduce code with simple, expressive APIs in Python, SQL, or Scala. DataFrames allow filtering, aggregation, and joins with single-line commands, while interactive shells (Jupyter, Spark-Shell) enable rapid experimentation. This reduces onboarding time for new engineers and lets teams focus on insights rather than infrastructure.
3. Unified Engine: Consolidate Your Data Stack
- One framework for batch, streaming, ML, and graphs.
Unlike legacy systems requiring separate tools for batch, streaming, and machine learning, Spark handles all workloads in one framework. Process historical data (batch), live streams (Structured Streaming), and ML models (MLlib) using the same API – eliminating integration complexity and data silos.
4. Fault Tolerance: Self-Healing Pipelines
- RDD lineage tracks data transformations.
- Automatically recomputes lost data partitions.
Spark automatically recovers from failures using RDD lineage – a log of all data transformations. If a node crashes, lost partitions are recomputed from scratch rather than requiring backup copies. Combined with checkpointing for critical jobs, this ensures reliability at petabyte scale.
5. Scalability: From Prototype to Production
- Scales from a single laptop to clusters with thousands of nodes.
- Handles petabytes of data.
The same Spark code runs on a laptop for development and scales linearly to thousand-node clusters. It dynamically allocates resources via Kubernetes/YARN and processes datasets from gigabytes to petabytes without redesign.
Key Components of Apache Spark: The Building Blocks of Big Data Processing
Apache Spark’s power comes from its modular architecture, where each component serves a specific purpose while working seamlessly with others. Let’s explore these core elements that make Spark a versatile solution for diverse data challenges.
1. Spark Core – The heart of Apache Spark. It manages:
- Task scheduling & execution
- Memory management & fault tolerance
- Communication across distributed clusters
Spark Core is the base engine that handles essential distributed computing tasks. It manages memory allocation, task scheduling, and fault recovery across clusters. All other Spark libraries build upon Core’s capabilities, providing the infrastructure for distributed data processing.
2. Spark SQL – Used for querying structured data with:
- SQL-like syntax (
SELECT * FROM table WHERE condition) - Compatibility with traditional databases & data lakes
- Integration with DataFrames for high-level data processing
Spark SQL brings relational database capabilities to big data environments. It allows querying data using standard SQL syntax while supporting integration with various data formats like Parquet, JSON, and JDBC databases. The DataFrame API provides a convenient way to manipulate structured data with optimized execution.
3. Spark Streaming – Enables real-time data processing:
- Works with Kafka, Flume, and AWS Kinesis
- Handles continuous data streams for real-time analytics
- Example use case: Fraud detection in financial transactions
This component enables processing live data streams with the same simplicity as batch operations. Spark Streaming divides continuous data into micro-batches, allowing near real-time analytics for applications like fraud detection and IoT monitoring while maintaining fault tolerance.
4. MLlib (Machine Learning Library) – Spark’s built-in ML library for:
- Clustering, classification, regression
- Recommendation systems (e.g., Netflix, Amazon)
- Anomaly detection in IoT and security analytics
MLlib delivers a comprehensive library of machine learning algorithms optimized for distributed environments. From classification to collaborative filtering, it provides tools for the entire ML pipeline, including feature extraction, model training, and evaluation, all designed to work efficiently on large datasets.
5. GraphX – Optimized for graph analytics:
- Helps analyze relationships in social networks (e.g., Facebook friend suggestions)
- Finds shortest paths in logistics and transportation networks
For analyzing connected data like social networks or recommendation systems, GraphX offers a distributed graph computation framework. It provides fundamental graph operators and algorithms while integrating with Spark’s core data processing capabilities.
These components work together to create a unified platform that handles diverse data processing needs – from batch analytics to real-time machine learning – all within a single, cohesive system. The modular design allows organizations to adopt only the components they need while maintaining the flexibility to expand their usage as requirements evolve.
Real-World Use Cases of Apache Spark: Transforming Industries with Data
Apache Spark powers mission-critical systems across every major industry, enabling organizations to process massive datasets and extract real-time insights. Here’s how leading companies leverage Spark’s capabilities to solve complex challenges and drive innovation.
1. Autonomous Vehicles: Real-Time Sensor Processing
Companies like Tesla and Waymo use Spark Streaming to analyze millions of data points per second from vehicle sensors, cameras, and LiDAR systems. Spark enables:
- Instant obstacle detection and collision avoidance
- Continuous learning from fleet-wide driving patterns
- Real-time route optimization based on traffic conditions
2. Financial Fraud Prevention
Major financial institutions (JPMorgan, PayPal) deploy Spark for:
- Real-time transaction monitoring (analyzing 500K+ transactions/minute)
- Machine learning models that adapt to new fraud patterns
- Reduced false positives through behavioral analysis
3. Personalized Media Recommendations
Streaming platforms (Netflix, Spotify, YouTube) utilize Spark’s MLlib to:
- Process billions of user interactions daily
- Update recommendation models in near real-time
- Test multiple algorithms simultaneously through A/B testing
4. Climate Science & Environmental Monitoring
NASA and NOAA process petabytes of satellite imagery with Spark to:
- Model climate change patterns with unprecedented granularity
- Predict extreme weather events days in advance
- Track deforestation and ice melt in real-time
5. IoT & Smart Manufacturing
Tesla’s factories leverage Spark to:
- Monitor equipment sensors for predictive maintenance
- Analyze production line efficiency in real-time
- Optimize supply chain logistics using weather/traffic data
Conclusion
Apache Spark has revolutionized big data processing by combining speed, simplicity, and scalability. Whether you’re analyzing terabytes of historical data or detecting fraud in real-time transactions, Spark provides the tools to turn raw data into actionable insights.
Apache Spark transformed the world of big data by providing a faster, scalable, and more user-friendly alternative to traditional frameworks like Hadoop.
Whether you’re working on real-time analytics, machine learning, or complex data processing, Spark is a powerful tool that helps businesses and researchers extract insights faster and with greater efficiency.
As data volumes grow exponentially and real-time insights become business-critical, Spark’s architecture positions it to remain the cornerstone of data infrastructure for the foreseeable future.
See you in the next post, where we’ll dive deep into Spark’s architecture – exploring how its ingenious design delivers these revolutionary capabilities! 🚀