The Silent Force Behind Modern Data
Imagine ordering a ride on Uber. The app matches you with a driver in seconds, calculates the fare in real time, and updates your route dynamically—all while processing millions of such requests globally at the same time. Now, think about LinkedIn tracking every profile view, Netflix recommending shows based on your latest binge, or banks detecting fraud before a transaction even completes. What makes all this possible?
Apache Kafka.!!
Most engineers have heard of Kafka, but few truly grasp its role. It’s not just another messaging system or a fancy database—it’s the central nervous system of real-time data. Kafka quietly powers the digital world, yet remains misunderstood. Some call it a “distributed log,” others a “message broker,” but in reality, it’s something far more powerful: a unified event streaming platform that redefines how data moves.
Why Should You Care?
If you’re a developer, data engineer, or tech enthusiast, Kafka is no longer optional. Companies like Uber, Airbnb, and LinkedIn process trillions of events per day using Kafka. It’s the backbone of event-driven architectures, microservices, and real-time analytics. But here’s the catch—most tutorials oversimplify it as just a “message queue,” missing its true potential.
The Kafka Mindset Shift
Traditional systems treat data as static records—databases store it, APIs retrieve it, and queues move it. Kafka flips this model:
- Data is a continuous stream, not a series of isolated events.
- Systems react in real time, not through periodic batch jobs.
- Decoupling is mandatory—producers and consumers never talk directly.
This shift is why Kafka dominates modern data infrastructure. It’s not just about speed (though it handles millions of messages per second with sub-10ms latency). It’s about rethinking how data flows in a world where real-time isn’t a luxury—it’s the standard.
So, if you’ve ever wondered how companies like Netflix personalize recommendations instantly or how financial systems detect fraud in milliseconds, the answer is Kafka. And by the end of this guide, you’ll not only understand it—you’ll see why mastering Kafka could be your next career accelerator.
Kafka’s Three Core Superpowers: More Than Just a Message Queue
Most engineers first encounter Kafka as “yet another messaging system.” But here’s the truth they rarely tell you: Kafka is to traditional message queues what a smartphone is to a rotary phone. It doesn’t just pass messages – it revolutionizes how data moves through your systems. Let’s break down its three fundamental capabilities that make it indispensable in modern architecture.
Superpower #1: The Event Streaming Nervous System
Imagine your company’s data as electrical signals in a human body. Traditional systems work like old telephone switchboards – connecting one point to another with tedious manual patching. Kafka operates like a central nervous system, where every event (a user click, payment, or sensor reading) flows instantly to every system that needs it.
This is why Netflix uses Kafka to process 5 billion events daily for recommendations. Each “play” event doesn’t just update your watch history – it simultaneously:
- Adjusts recommendations
- Updates trending algorithms
- Informs content licensing decisions
- Triggers billing for pay-per-view
All in under 100 milliseconds. That’s the power of true event streaming – data becomes alive, flowing where it’s needed the moment it’s born.
Superpower #2: The Ultimate Decoupling Layer
Here’s a dirty secret of enterprise IT: Most “integrated” systems are a fragile web of point-to-point connections. I once saw a bank with 120 services communicating directly – a change to one required testing 119 integrations. Kafka solves this through ruthless decoupling.
Consider a food delivery app:
- The order service publishes an “OrderPlaced” event
- Dozens of services consume it independently:
- Driver app finds couriers
- Kitchen system starts cooking
- Payment service authorizes charges
- Analytics tracks conversion rates
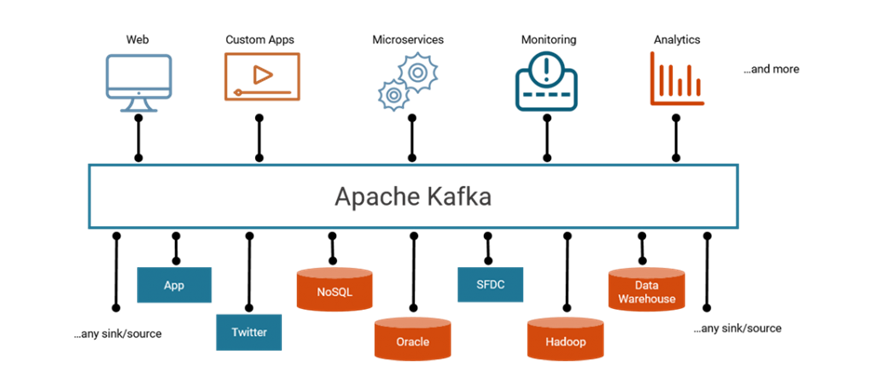
Kafka’s event streaming connects countless producers and consumers in real-time
None know about the others. The kitchen could crash without affecting payments. You can add new services without modifying producers. This architectural purity is why Walmart reduced integration costs by 78% after adopting Kafka.
Superpower #3: Unkillable Data Durability
Traditional message queues lose data when systems crash. Kafka’s distributed commit log approach makes data virtually indestructible. Here’s how it works:
- Every message is written to disk immediately
- Replicated across 3+ servers (configurable)
- Stored for days/weeks (even after consumption)
- Can replay entire histories like a time machine
This durability enabled PayPal to reduce fraud by $700 million annually. Their fraud detection:
- Gets every transaction via Kafka
- Analyzes patterns in real-time
- Can reprocess months of data when models improve
- Never loses a transaction, even during outages
The Hidden Cost: When Kafka is Overkill
With great power comes great responsibility. Kafka shines when you need:
- 10,000+ events per second
- Multiple consumer groups
- Strict ordering guarantees
- Historical replay capability
For simple task queues or sub-1K msg/sec systems? A traditional queue might save you 40% in operational overhead. The wisest engineers know both tools and choose accordingly.
Up Next: We’ll get hands-on with code – from local setup to your first event pipeline. Because real understanding comes from doing, not just reading.
Kafka’s Key Components: The Nuts and Bolts
At its core, Kafka is a distributed system—meaning it’s made up of multiple moving parts that work together seamlessly. If you’ve ever wondered how Kafka handles millions of messages per second without breaking a sweat, the answer lies in its architecture. Let’s meet the key players.
At its core, Kafka is a symphony of specialized components working in harmony. Let’s pull back the curtain on the machinery that makes real-time data magic happen.
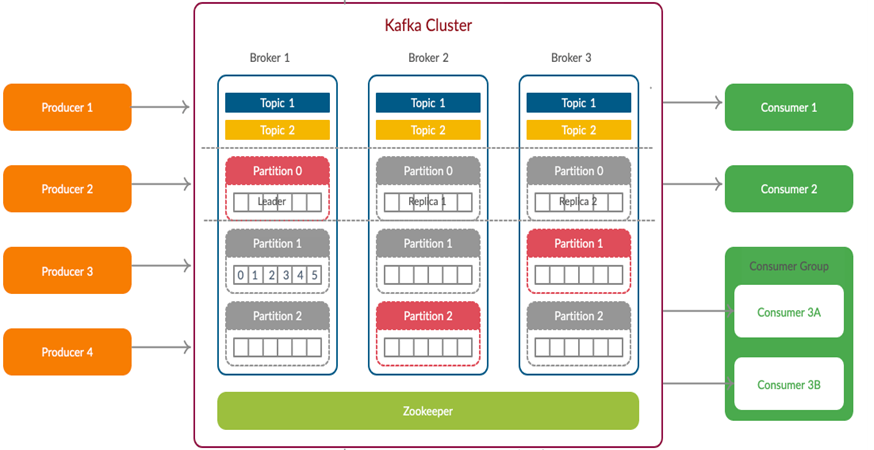
Kafka’s distributed design: Producers write to partitioned topics, brokers store data, and consumers process events in real-time. (Source: Confluent)
1. Producers: Feeding Data into Kafka
Producers are applications or services that publish (write) messages to Kafka topics. They don’t wait for a response—they push data at high speed and let Kafka handle the rest. Think of them like journalists sending breaking news to a newspaper office. Whether it’s a user click, a stock trade, or a sensor reading, producers ensure the data gets into Kafka as fast as possible.
A key trait of good producers? They don’t care who consumes the data—they just send it and move on. This is Kafka’s first rule of decoupling.
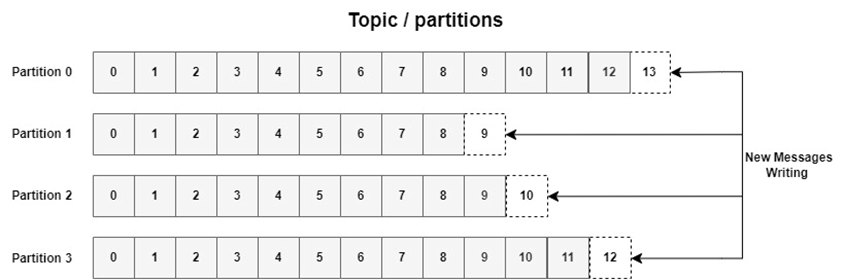
2. Topics & Partitions: Organized Chaos
A topic is like a category or a folder where messages are stored (e.g., user_signups, payment_transactions). But here’s where Kafka gets smart: each topic is split into partitions.
Imagine a library where books (messages) are stored on multiple shelves (partitions) instead of one giant pile. This allows:
- Parallel processing (multiple consumers reading different partitions at once)
- Fault tolerance (if one partition fails, others keep working)
- Scalability (adding more partitions increases throughput)
The number of partitions defines how much data Kafka can handle simultaneously. Too few, and you bottleneck performance. Too many, and you add unnecessary overhead.
Pro Tip: The partition count you choose during topic creation becomes your scalability ceiling. Start small (2-3 partitions), then expand as needed.
3. Brokers: The Storage Powerhouses
Brokers are Kafka’s servers—the machines that store data and handle read/write requests. A Kafka cluster typically has multiple brokers (3 or more for fault tolerance).
Each broker holds a subset of partitions, and Kafka automatically replicates data across brokers. If one crashes, another takes over instantly. This is why companies like LinkedIn and Uber trust Kafka—it’s built to never lose data, even during outages.
Brokers are Kafka’s workhorses—servers that store and manage your data. A healthy Kafka cluster runs 3+ brokers for fault tolerance. Their key responsibilities:
- Persist messages to disk (even if consumed)
- Replicate data across the cluster (no single point of failure)
- Serve requests from producers/consumers
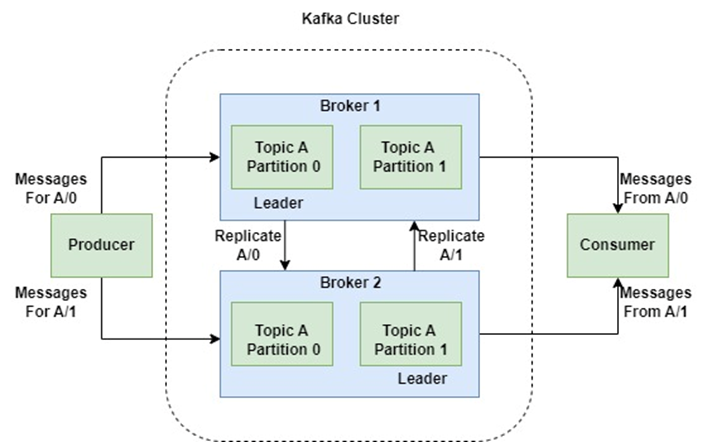
When LinkedIn’s Kafka cluster handles 7 trillion messages daily, it’s brokers doing the heavy lifting.
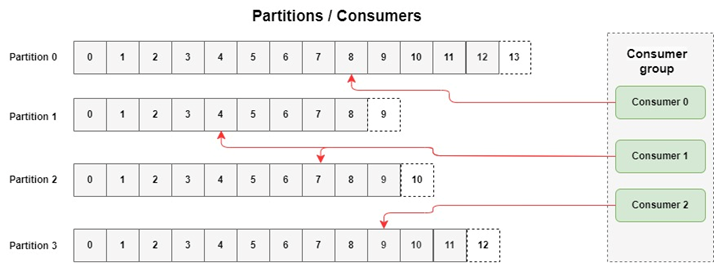
4. Consumers: Reading Data from Kafka
Consumers read messages from Kafka topics. Unlike traditional queues (where messages disappear after reading), Kafka consumers can:
- Rewind and replay old messages (like rewinding a video)
- Scale horizontally (multiple consumers working in a group)
- Process data in real-time (no waiting for batches)
For example, a fraud detection system might consume payment events, analyze them, and flag suspicious activity—all in milliseconds.
5. ZooKeeper: The Legacy Coordinator
ZooKeeper has long been Kafka’s “brain”—managing broker metadata, leader elections, and cluster health. However, newer Kafka versions (3.0+) are phasing it out (thanks to KIP-500) to simplify operations. Until then, it remains a critical (but often overlooked) piece of the puzzle.
Hands-On: Your First 5 Minutes with Kafka
Enough theory—let’s make Kafka come alive. In this section, you’ll run a Kafka cluster locally and publish your first event in under 5 minutes. No complex setup required—just Docker and a terminal.
Step 1: Launch Kafka with Docker
Kafka requires ZooKeeper (for now) and brokers. Instead of installing them separately, Docker Compose makes it trivial:
# docker-compose.yml
version: '3'
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.0.1
environment:
ZOOKEEPER_CLIENT_PORT: 2181
kafka:
image: confluentinc/cp-kafka:7.0.1
depends_on:
- zookeeper
ports:
- "9092:9092"
environment:
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9092Run it with:
docker-compose up -dCongrats! You now have a Kafka cluster running.
Step 2: Create Your First Topic
Topics are where messages live. Let’s create one called test-topic:
docker exec -it kafka \
kafka-topics --create \
--topic test-topic \
--partitions 3 \
--replication-factor 1 \
--bootstrap-server localhost:9092Key choices:
- 3 partitions (for parallel processing)
- Replication factor 1 (sufficient for local testing)
Step 3: Publish and Consume Messages
Produce a message (like sending an email):
docker exec -it kafka \
kafka-console-producer \
--topic test-topic \
--bootstrap-server localhost:9092
> Hello, Kafka!Consume it (like checking your inbox):
docker exec -it kafka \
kafka-console-consumer \
--topic test-topic \
--from-beginning \
--bootstrap-server localhost:9092
Hello, Kafka!You’ve just:
- Run a distributed system on your laptop
- Experienced Kafka’s pub-sub model firsthand
- Verified data persistence (messages survive consumer restarts)
Pro Tip: Try opening two consumer terminals simultaneously to see how partitions distribute messages.
Take It Further: Real-World Project Idea
Build a real-time tweet analyzer:
- Use Twitter API to stream tweets into Kafka
- Process them with a Python consumer
- Calculate sentiment scores
When to Use Kafka (And When to Avoid It)
Apache Kafka is a powerhouse for real-time data, but it’s not always the right tool. Let’s break down its strengths and limitations clearly.
✅ Ideal Use Cases for Kafka
Kafka excels when you need:
✔ High-throughput streaming (10K+ messages/sec)
- Example: Uber processes 4+ trillion messages daily for ride tracking.
✔ Decoupled microservices
- Producers and consumers never communicate directly—reducing spaghetti integrations.
✔ Event sourcing & replayability
- Stores immutable logs (e.g., financial transactions) for debugging or reprocessing.
✔ Durability & fault tolerance
- Replicates data across brokers; survives machine failures.
✔ Real-time analytics
- Fraud detection, IoT sensor data, live recommendations.
❌ When to Avoid Kafka
Consider simpler alternatives if:
✖ Low throughput (<1K msgs/sec)
- RabbitMQ or Redis are easier to manage for small-scale apps.
✖ Temporary messaging
- Background jobs or request/reply patterns don’t need Kafka’s persistence.
✖ Limited DevOps resources
- Kafka requires tuning (partitioning, ZooKeeper, brokers). Managed services (Confluent Cloud) help.
✖ Wildcard topic subscriptions
- Kafka requires explicit topic names—no regex support.
Conclusion: Streaming Data as a Superpower
Apache Kafka represents more than just technology – it’s a new paradigm for building responsive, data-driven systems. Throughout this guide, we’ve explored how Kafka’s distributed architecture enables real-time processing at unprecedented scale.
Key Lessons to Remember:
- Kafka’s true power lies in its ability to decouple systems while maintaining durability
- The publish-subscribe model enables both real-time and historical data processing
- Proper partitioning strategies are crucial for achieving maximum throughput
From Theory to Production
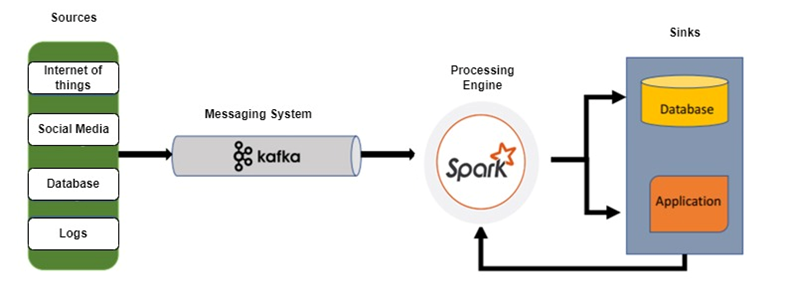
For those looking to see these concepts applied to a real-world scenario. Explore my Outlier Detection Over Streaming Data of Human Activities., where I built a complete Kafka-Spark pipeline that:
✔ Processes continuous sensor streams to detect abnormal patterns
✔ Balances throughput and accuracy for real-world IoT deployments
✔ Serves as a blueprint for stateful stream processing
Where to Go From Here:
- Experiment with the Docker setup from Section 4
- Explore Kafka’s admin CLI to monitor topic performance
- Read the official Kafka documentation for advanced configuration
“Streaming isn’t the future—it’s the present. Start small, think in events, and scale with confidence.”
We’ve explored Kafka’s core concepts—from its distributed architecture to hands-on message streaming. Stay tuned for our next post 📢.